Теорія черг (Queueing Theory)
Радість інженерії полягає в тому, щоб знайти пряму лінію на подвійній логарифмічній діаграмі.
- Томас Кеніг
Теорія черг (Queueing Theory) один з принципів LeSS Framework.
Теорія черг дає уявлення про те, чому традиційна розробка є невиправдано повільною і що з цим робити. У великомасштабній розробці часто буває так, що "одна" функція (до розділення) є приголомшливо гігантською. У таких доменах особливо корисно бачити, що великі партії та довгі черги дійсно існують, і проблеми, які вони викликають.
Важко виправити проблему, про яку ви не знаєте. А теорія черг вказує на деякі способи покращення. Цей інструмент мислення особливо актуальний у великих масштабах, оскільки великі змінні партії робіт - такі поширені в традиційній моделі - мають нелінійний вплив на тривалість циклу - вони дійсно можуть все зіпсувати,

Цікава невідповідність: Теорія черг - математичний аналіз того, як матеріали рухаються через систему з чергами - була розроблена, щоб зрозуміти і поліпшити пропускну здатність телекомунікаційних систем - систем з великою кількістю варіативності і випадковостей, подібних до розробки продукту.
Як наслідок, телекомунікаційні інженери розуміють основні ідеї. І все ж, люди, які розробляють телекомунікаційну інфраструктуру (телекомунікації - це сфера великих продуктів), рідко бачать, що це може бути застосовано до їхньої системи, щоб скоротити середню тривалість циклу в їхніх процесах розробки.
Співробітники Toyota дізнаються про статистичну варіативність і наслідки теорії черг; це відображено в принципі ощадливого вирівнювання для зменшення варіативності і, в більш загальному плані, в ощадливому фокусі на менших партіях і тривалості циклів для переходу до потоку.
Перш ніж зануритися безпосередньо в тему, зверніть увагу, що ощадливість іноді описують як зосередження на меншому розмірі партії (робочого пакету), коротших чергах і швидшому часі циклу. Швидке створення цінності.
Ощадливість - це набагато більше, ніж це - її стовпами є повага до людей і постійне вдосконалення, що спирається на фундамент менеджерів-викладачів, які володіють ощадливим мисленням. Управління чергами (ліміти WIP, ...) є корисним, але це лише інструмент, далекий від суті ощадливого мислення.
Як стане очевидним, LeSS підтримує управлінські наслідки теорії черг.
Попередження щодо міфів про закон Літтла
Перш ніж заглибитися в теорію черг, слід розвіяти поширений міф, пов'язаний з теорією черг, який поширюється у спільноті ощадливої та гнучкої розробки (навіть у деяких підходах до масштабування), і який слід швидко розвіяти.
Ви можете знайти безліч статей, в яких стверджується, що закон Літтла доводить, що зменшення рівня WIP зменшить середній час циклу. Якби ж то було так! На жаль, доказ Літтла залежить від набору умов/припущень, які повинні бути вірними, щоб динаміка була правдивою. І, на жаль, ці умови жодним чином не гарантуються і навіть не є загальновизнаними у сферах з високою мінливістю, таких як розробка програмного забезпечення.
Наївне просування або виправдання закону Літтла в розробці програмного забезпечення добре розбирається в аналізі Деніела Ваканті під назвою "Помилка Літтла" (англ. Little's Flaw).
Зменшення рівня WIP - гідна мета і важлива в LeSS. WIP - це одне з марнотратств в ощадливому мисленні, тому що воно затримує повернення інвестицій, приховує дефекти, знижує прозорість, серед інших проблем.
А зменшення рівня WIP оголює слабкі місця. Але, на жаль, у розробці програмного забезпечення немає гарантії, що зменшення WIP автоматично зменшить середню тривалість циклу.
Конкурувати за коротший час циклу (Compete on Shorter Cycle Times)
Ощадлива організація з розробки продукту зосереджена на створенні цінності за найкоротший можливий стійкий час циклу, зосереджена на пропускній здатності системи, а не на завантаженості людей. Співробітники Toyota, родоначальники ощадливого мислення, є майстрами все швидшого і швидшого (коротшого) часу циклу, не перевантажуючи при цьому людей.
Які існують технологічні цикли або тривалість циклу в розробці продукту?
- "від ідеї до готівки" для одного релізу
- "від концепції до реалізації" для однієї функції
- потенційно можливий час відвантаження; як часто ви могли б відвантажувати?
- час компіляції (всього програмного забезпечення)
- від "готовності до пілотування" до часу доставки
- час розгортання для тестування (на вбудованому обладнанні)
- час на аналіз та проектування
Ключові показники ефективності (KPI) в ощадливому виробництві не зосереджені на використанні або зайнятості працівників, які виконують ці процеси. Скоріше, ощадливі KPI більше зосереджуються на тривалості циклу виробництва.
З огляду на це, застереження: Вимірювання зазвичай призводить до дисфункції або "гри" системи через неоптимізацію для досягнення гарного результату [Austin96]. Це особливо стосується "нижчих" технологічних циклів. Найбільш важливими є цикли вищих рівнів, такі як потенційно можливий час відвантаження та час від "замовлення до готівки" або "замовлення до доставки" (квінтесенція циклів).
Що б це означало, якби ви могли здійснювати доставку вдвічі або вчетверо швидше, не перевантажуючи людей? А з іншого боку, яка ціна затримки?
Розглянемо переваги швидкої реалізації з точки зору прибутку протягом життєвого циклу, отриманих можливостей, реакції на конкуренцію та інновацій. Для більшості компаній - не для всіх - це буде надзвичайною перевагою.
Вдвічі менше часу - не означає вдвічі менше витрат - Коли люди чують "вдвічі менше часу", вони можуть подумати: "Вдвічі більше продуктів, функцій чи релізів - вдвічі більша ефективність". Але це може призвести до збільшення транзакційних витрат, накладних витрат на кожен цикл. Частіша доставка може збільшити витрати на тестування або розгортання - або ні, як буде видно далі.
Вдвічі менше часу - це не вдвічі більше витрат - Перш ніж ви відкладете свою таблицю з аналізом транзакційних витрат, зачекайте. Існує тонкий зв'язок між тривалістю циклу, транзакційними витратами та ефективністю, який незабаром буде досліджений - секрет вражаючої ефективності Toyota та інших підприємств з ощадливим мисленням...
Управління чергами (Queue management) - Існує безліч стратегій для скорочення часу циклу; як ощадливі, так і гнучкі практики пропонують цілу низку ефективних засобів. Один з інструментів є предметом цього розділу - управління чергами.
Управління чергою для скорочення часу циклу (Queue Management to Reduce Cycle Time)
"Черги існують лише у виробництві, тому теорія черг та управління чергами не застосовуються до розробки продукту". Це поширена помилка. Як уже згадувалося, теорія черг виникла не у виробництві, а в дослідженнях операцій для підвищення пропускної здатності телекомунікаційних систем з високою мінливістю.
Більше того, багато груп розробників - особливо ті, що застосовують ощадливі або гнучкі практики - застосовують управління чергами на основі теорії черг як для розробки продуктів, так і для управління портфелем. До такого висновку прийшли дослідники з Массачусетського технологічного інституту та Стенфорду:
Бізнес-підрозділи, які прийняли цей підхід [управління чергами для управління портфелем і продуктами], скоротили середній час розробки на 30-50%. [AMNS96].
Черги в розробці продуктів та управлінні портфелем (Queues in Product Development and Portfolio Management)
Приклади черг у розробці та управлінні портфелем?
- продукти або проекти в портфоліо
- нові функції для одного продукту
- детальні технічні завдання, що очікують на розробку
- проектні документи, що очікують на кодування
- код, що очікує на тестування
- код одного розробника, який очікує на інтеграцію з іншими розробниками
- великі компоненти, що очікують на інтеграцію
- великі компоненти та системи, що очікують на тестування
У традиційній послідовній розробці існує багато черг частково виконаної роботи, відомих як черги незавершеного виробництва (work-in-progress або WIP); наприклад, специфікаційні документи, які очікують на програмування, і код, який очікує на тестування.
На додаток до черг незавершеного виробництва існують черги з обмеженими або спільними ресурсами, наприклад, накопичення запитів на використання дорогої тестової лабораторії або одиниці тестового обладнання.
Черги - це проблема (Queues Are a Problem)
По-перше, якщо немає черг - і немає багатозадачності, яка штучно створює видимість того, що черги зникли, - то система буде рухатися до потоку, принципу ощадливості та досконалості, який полягає в тому, що цінність доставляється без затримок. Кожна черга створює затримку, яка гальмує потік. Конкретніше, чому черги є проблемою?
Черги WIP (WIP Queues)
Черги WIP при розробці продукту рідко розглядаються як черги з кількох причин; можливо, головна з них полягає в тому, що вони, як правило, невидимі - біти на комп'ютерному диску. Але вони існують, і, що важливіше, вони створюють проблеми. Чому?
Черги WIP (як і більшість черг) збільшують середній час циклу і зменшують доставку цінності, а отже, можуть знизити прибуток протягом усього терміну служби.
З точки зору ощадливого мислення, черги незавершеного виробництва вважаються відходами, а отже, мають бути усунені або скорочені:
- WIP Черги незавершеного виробництва мають вищезгаданий вплив на тривалість циклу.
- WIP Черги незавершеного виробництва - це частково виконані запаси (специфікацій, коду, документації, ...), на які було витрачено час і гроші, але які не принесли жодної віддачі.
- Як і будь-яка інвентаризація, черги незавершеного виробництва приховують дефекти - і дозволяють їх реплікацію - тому що купа інвентарю не була спожита або протестована наступним процесом для виявлення прихованих проблем; наприклад, купа неінтегрованого коду.
- Історія: Ми бачили традиційну продуктову групу, яка близько року працювала над функцією "розриву угоди". Потім менеджмент продукту вирішив видалити її, оскільки вона загрожувала загальному випуску, а ринок змінився. Перепланування зайняло багато тижнів. Загалом, черги WIP впливають на вартість і здатність реагувати на зміни (видалення і додавання), тому що (1) час і гроші були витрачені на незавершену видалену роботу, яка не буде реалізована, або (2) WIP видаленого елемента може бути переплутаний з іншими функціями, або (3) функція, яку потрібно додати, може бути запущена із запізненням через високий рівень WIP на даний момент.
Як буде показано далі, існує ледь помітний, але потенційно потужний побічний ефект покращення системи, який може виникнути в процесі ліквідації черг ПІВ.
Черги на спільні ресурси (Shared-Resource Queues)
На відміну від черг WIP (які не сприймаються такими, якими вони є), черги на спільні ресурси частіше сприймаються як черги - і розглядаються як проблема. Вони явно і болісно сповільнюють роботу людей, затримують зворотній зв'язок і розтягують час циклу. "Нам потрібно протестувати наш новий код на цьому принтері в тестовій лабораторії. Коли вона буде вільна?"
План А: Ліквідувати (а не керувати) чергами
Суть в тому, що (зазвичай) черги - це проблема. З огляду на це, ви можете зробити висновок, що першою лінією захисту від цієї проблеми є зменшення розміру партії та черги, оскільки це класичні стратегії управління чергами. Проте, існує рішення "гордієвого вузла", яке слід розглянути в першу чергу...
У решті цієї глави ми дійсно розглянемо скорочення часу циклу за допомогою управління партіями та розміром черги. Але вся ця стратегія управління повинна бути планом Б. Краще почати з плану А:
План А у вирішенні проблеми черги полягає в тому, щоб повністю викорінити чергу, назавжди, шляхом зміни системи: системи організації, системи розвитку, інструментів, процесів, практик, політик тощо.
Мисліть нестандартно і скорочуйте час циклу, змінюючи систему так, щоб черги більше не існували - усуваючи вузькі місця та інші чинники, які створюють черги. Ці обмеження та черги, які вони породжують, можуть бути створені або усунуті самою природою системи розробки та її інструментів.
Припустимо, що існуюча система базується на послідовній розробці з окремими спеціалістами/функціональними працівниками або групами. Існують черги WIP: Група аналітиків передає робочі пакети специфікацій групі програмістів, яка передає робочі пакети коду групі тестування, яка передає код групі розгортання.
Стандартна відповідь на покращення управління чергами полягає у зменшенні лімітів незавершеного коду та розмірів черг. Але такий підхід має справу лише з вторинними симптомами існуючої системи.
Існує глибша альтернатива, яка значно покращить час циклу: Відмовтеся від цієї системи та вузьких місць і черг незавершеного виробництва, які вона породжує.
Якщо ви приймете крос-функціональні команди розробників, які створюють повні функції (аналіз, програмування і тестування), не передаючи роботу іншим групам, і які застосовують автоматизовану розробку, керовану приймальними тестами, і автоматизоване безперервне розгортання, вищезгадані черги незавершеного продукту зникнуть завдяки переходу від послідовної до паралельної розробки.
Цей підхід відображає бачення LeSS, що полягає в усуненні першопричин: зміна організаційної структури для вирішення основних проблем.
Усунення фальшивої черги (Fake Queue Elimination)
Припустимо, ви зайняті роботою над завданням A, а в черзі стоять завдання B, C, D і E. Справжнє скорочення черги полягає в тому, щоб працювати над усіма цими завданнями більш-менш одночасно - високий рівень багатозадачності та використання.
Багатозадачність є одним з видів ощадливого марнотратства, оскільки, як ми скоро побачимо, теорія черг показує, що вона збільшує середній час циклу, а не зменшує його. І цей фальшивий підхід фактично збільшує WIP в ім'я його скорочення! Погана ідея.
Не збільшуйте багатозадачність або коефіцієнт використання, щоб створити ілюзію, що черги зменшилися, а система покращилася; скоріше, покращуйте систему так, щоб усунути вузькі місця та інші чинники, які створюють черги.
План Б: Керуйте чергами, коли ви не можете їх усунути (Plan B: Manage Queues When You Can’t Eliminate Them)
Традиційні черги WIP можуть бути усунені шляхом переходу на LeSS з міжфункціональними командами розробників, використанням TDD прийняття та безперервним розгортанням. Вигнані та зниклі за допомогою плану А - змінити систему. Це ідеальне рішення, рекомендоване в LeSS.
Проте, черги можуть залишатися і залишаються, наприклад
- черги ресурсів спільного використання, наприклад, в тестовій лабораторії
- черга запитів на функціонал у Product Backlog
- черги WIP, тому що (1) план А ще неможливий (глибокі зміни у великих групах вимагають часу), або (2) інструменти і методи, такі як перехід від ручного до повністю автоматизованого тестування, слабкі і повільно вдосконалюються.
Незалежно від того, які черги залишаються - і, як мінімум, Product Backlog залишиться - ви можете покращити середній час циклу за допомогою Плану Б в управлінні чергами:
План Б: Для черг, які неможливо ліквідувати, покращити середній час циклу, зменшивши розмір партій у чергах, зменшивши ліміти ПІВ та розміри черг, а також зробивши кожну партію більш-менш однаковою за розміром.
У LeSS менший пакет означає менший робочий пакет елементів або функцій для розробки в спринті. Однакові за розміром партії означають, що кожна з них оцінюється як приблизно рівна за зусиллями.
Конкретно, як застосувати це в LeSS? Це буде розглянуто пізніше, але спочатку перейдемо до теорії черг...
Теорія черг (Queueing Theory)
Для цього може знадобитися важка праця або новий погляд, але не потрібно багато теорії, щоб "керувати чергами", викорінюючи їх. З іншого боку, коли вони все ж таки існують, корисно знати, як з ними боротися за допомогою мисленнєвого інструменту теорії черг.
Формальна модель для оцінки процесів (A Formal Model for Evaluating Processes)
Ви можете прийняти на віру, що черги з меншими партіями товарів однакового розміру покращують середній час циклу. Або ні. У будь-якому випадку, корисно знати, що це припущення не базується на думці, а ґрунтується на формальній математичній моделі, яку можна продемонструвати. Можна міркувати про деякі аспекти процесу розробки, використовуючи формальну модель. Наприклад:
- Гіпотеза: Найшвидше виконувати послідовну ("водоспадну" або V-модель) розробку з передачею великих пакетів між групами.
- Гіпотеза: Найшвидше люди або групи можуть працювати над багатьма проектами одночасно з високим коефіцієнтом використання ресурсів і багатозадачністю.
Розуміння теорії черг, незалежно від думки, може показати, чи допомагають ці гіпотези скоротити середній час циклу.
Тема відносно проста; сценарій охоплює ключові елементи...
Властивості стохастичної системи з чергами (Qualities of a Stochastic System with Queues)
Уявіть собі Лос-Анджелес або Бенгалуру в годину пік. Якимось дивом немає аварій і всі смуги руху вільні. Рух щільним і повільним, але все ж таки відбувається. За короткий проміжок часу на трьох різних великих чотирисмугових автомагістралях (дванадцять смуг) стаються аварії, і три смуги закриваються - тільки дев'ять смуг залишаються відкритими.
Бум! Перш ніж ви встигнете сказати: "Чому я не купив гелікоптер?", більша частина міста застрягає в заторі. Коли аварії нарешті ліквідують (від тридцяти до шістдесяти хвилин по тому), величезні черги розсмоктуються вічно. Спостереження:
- Нелінійний (Nonlinear) - коли автомагістраль завантажена від нуля до п'ятдесяти відсотків, вона йде як по маслу - практично без черг і затримок. Але від п'ятдесяти до ста відсотків стає помітним уповільнення, утворюються черги. Залежність завантаження від розміру черги нелінійна, а не плавне лінійне зростання від нуля.
- Затримки і перевантаження не починаються при завантаженості 99,99% - це не той випадок, коли все йде швидко і гладко на автомагістралі до того моменту, поки не досягне 100-відсоткової завантаженості дороги автомобілями. Швидше, все сповільнюється і затори виникають задовго до того, як пропускна здатність буде досягнута.
- Розчищення черги займає більше часу, ніж її створення - сорокап'ятихвилинне блокування в Лос-Анджелесі в годину пік створює черги, на розчищення яких потрібно більше сорока п'яти хвилин.
- Стохастичний, а не детермінований (Stochastic, not deterministic) - Існує варіація та випадковість з ймовірностями (це астохастична система): швидкість прибуття автомобілів, час на усунення блокування, швидкість виїзду автомобілів.
Це варто пояснити, якщо ви хочете зрозуміти, як поводяться системи, тому що, здається, всі ми, люди, не маємо інтуїтивного відчуття стохастичної та нелінійної якості систем з чергами. Інтуїція може підказувати, що вони детерміновані і поводяться лінійно.
Цей хибний "здоровий глузд" призводить до помилок в аналізі проблем та управлінні розробкою продукту. Ці спостереження - і помилки мислення - стосуються черг WIP у традиційній розробці продуктів і практично всіх інших черг.
Однією з поширених помилок мислення при розробці продукту є те, що черги, затримки і люди, які їх обслуговують, поводяться так, як показано на рисунку 1 - нерозуміння того, що "затримка починається лише тоді, коли шосе заповнене на 100 відсотків".
Але уповільнення починає відбуватися на магістралі задовго до того, як вона буде заповнена на 100 відсотків. Можливо, при 60-відсотковій завантаженості ви почнете помічати уповільнення - більшу середню тривалість циклу.
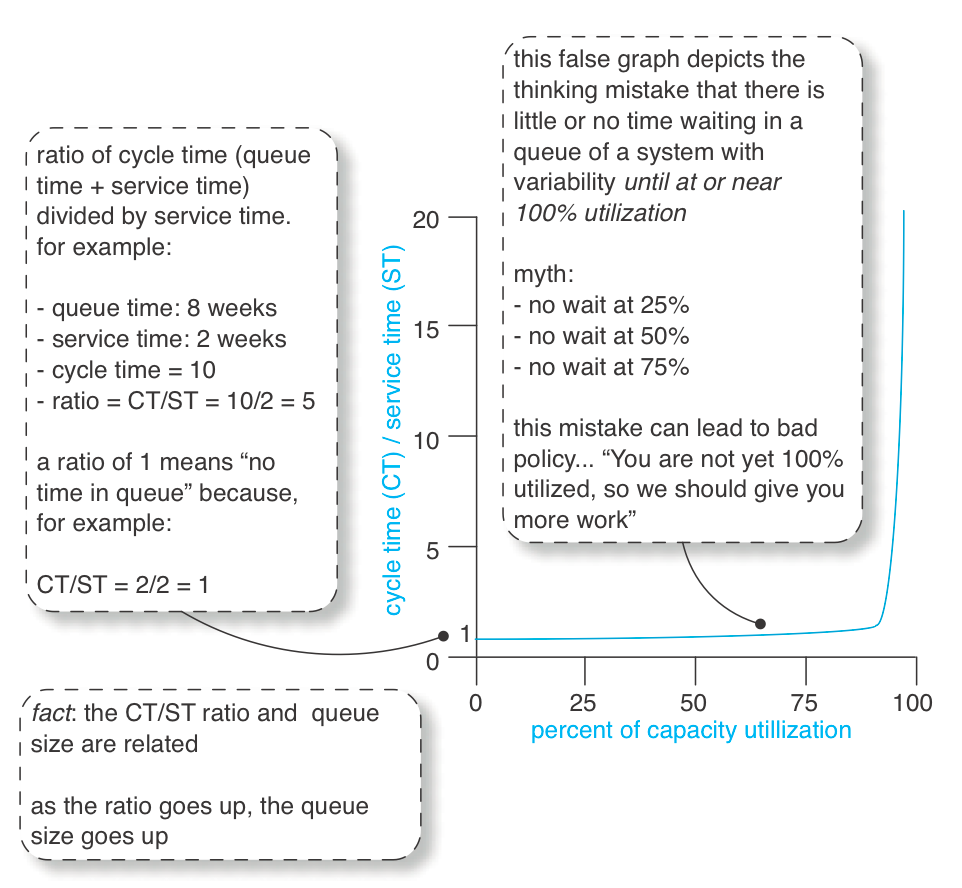
Нерозуміння того, що "затримка починається лише тоді, коли магістраль заповнена на 100 відсотків", призводить до того, що люди, які займаються розробкою продукту, зосереджуються на спробах скоротити час циклу за рахунок збільшення використання ресурсів, що призводить до більшої зайнятості, як правило, за рахунок більшої кількості багатозадачних завдань. Це помилка локальної оптимізації.
Що насправді відбувається з середньою тривалістю циклу, коли підвищується рівень використання речей чи людей у системі з варіативністю?
У тестовій лабораторії компанії Xerox є дорогі, великі цифрові друкарські машини. Часто виникає черга запитів на тестування одного з цих пристроїв із загальним ресурсом. Не розуміючи, як насправді працюють черги (тобто вважаючи, що вони працюють так, як показано на рис. 1), управлінський підхід полягав би в тому, щоб ці дорогі системи були зарезервовані і використовувалися майже 100 відсотків часу. Але реальність така, що повсюди існує мінливість - стохастична система. Тести надходять випадково, деякі швидко виходять з ладу, деякі тривають вічність, іноді обладнання ламається тощо. Ця ж мінливість поведінки стосується людей і черг роботи, над якими вони працюють.

Моделювання базової системи масового обслуговування з чергами (Modeling a Basic Single-Arrival System with Queues)
Як ці системи поводяться в дорожньому русі, в тестових лабораторіях або в традиційній розробці з людьми, які працюють з чергами WIP? Ви зрозуміли це з історії з трафіком. Математично поведінку можна змоделювати як варіації систем M/M. M/M означає, що швидкість прибуття в чергу є марковською і швидкість обслуговування є марковською. (Марковський: просте поняття - випадковий процес з ймовірностями (стохастичний), в якому майбутній стан не може бути детерміновано відомий з теперішнього стану; тобто, подібно до "безладної реальності").
Поширеною базовою моделлю черги є M/M/1/∞ - у ній є один сервер (наприклад, один тестовий принтер або команда) і нескінченна черга. (Черги розробки зазвичай не є нескінченними, але це спрощення не впливає на основну модель поведінки систем).
Тепер стає цікаво... Як у системі M/M/1/∞ цикл і час обслуговування пов'язані з використанням сервера - чи то тестового принтера, чи то людей, що працюють у черзі WIP? Див. поведінку очікування для базової системи M/M/1/∞. показує поведінку [Smith07].
Це середні значення у Див. поведінку очікування для базової системи M/M/1/∞, оскільки елементи мають випадкову варіабельність, наприклад:
- запити надходять у різний час з різними зусиллями
- тести або зусилля з програмування займають різний час
- люди працюють швидше або повільніше, хворіють, працюють довше або коротше
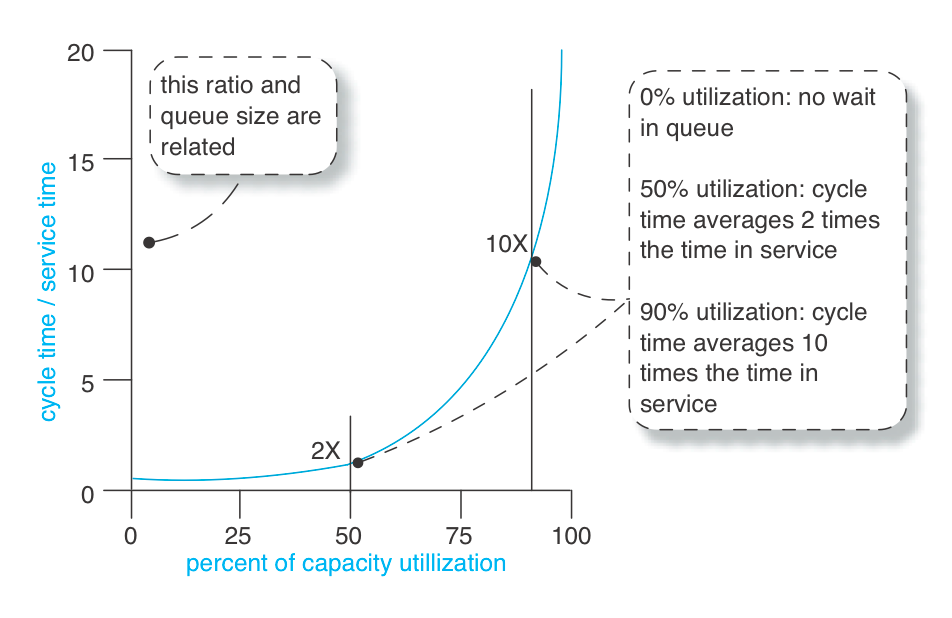
Важливо зрозуміти, що елемент (наприклад, вимога) починає стояти в черзі на обслуговування задовго до того, як люди будуть завантажені на 100 відсотків.
Цікаво також спостерігати за впливом збільшення завантаженості людей на тривалість циклу: Зі збільшенням завантаження в системі з великою варіативністю середня тривалість циклу погіршується, а не покращується.
Це контрінтуїтивно для пересічного бухгалтера чи консультанта з управління, якого навчили "підвищувати продуктивність за рахунок збільшення використання ресурсів". Більшість з них не знайомі з теорією масового обслуговування - як розуміти стохастичні системи з чергами (люди, що виконують роботу з мінливістю) - і тому демонструють помилкове мислення.
Саме ця мінливість реального світу створює в середньому збільшений розмір черги та час очікування при розробці продукту.
Саме ця мінливість реального світу створює в середньому збільшений розмір черги та час очікування при розробці продукту.
Моделювання пакетної системи з чергами (традиційна розробка) (Modeling a Batch System with Queues (Traditional Development))
Далі стає ще цікавіше (якщо ви можете в це повірити)... Базова система M/M/1/∞ передбачає, що один елемент (для тестування, аналізу, програмування, ...) надходить ізольовано - що елементи, які надходять, ніколи не об'єднуються в групи (або пакети).
Проте в традиційній розробці продукту робочі пакети надходять великими великими пакетами, такими як набори вимог, тестова робота або код, який потрібно інтегрувати. Або ж надходить "єдина" вимога, наприклад, "обробляти операції з деривативами на ринку облігацій Бразилії", яка насправді є пакетом під-вимог.
Цей останній момент дуже важливо відзначити, тому що велика вимога неминуче не проходить через систему як один робочий пакет, хоча "на відстані" вона помилково розглядається як один робочий пакет.
"Одна велика вимога сама по собі є партією" - це важливий момент, до якого ми повернемося пізніше.
Отже, замість простішої моделі з одним надходженням M/M/1/∞ (надходить один виріб), розглянемо систему M[x]/M/1/∞ (надходить партія виробів). Ця модель є кращою аналогією до традиційної розробки продукту.
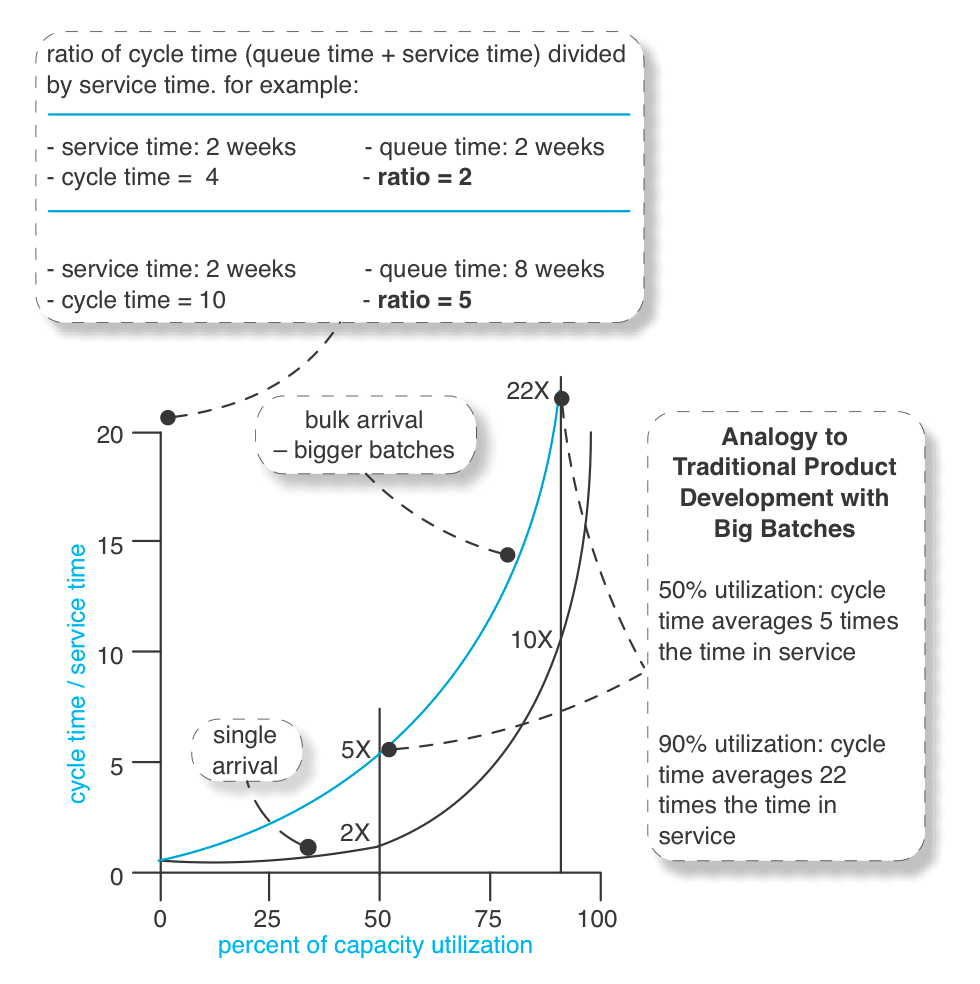
Тепер уявіть, що ви зазвичай даєте команді, яка завантажена на 50%, значно більші пакети вимог або "одну" гігантську вимогу, яка насправді охоплює велику кількість підвимог; вони надходять з певною випадковістю та різним розміром. Припустімо, що на виконання певного пакету Х або "однієї" великої вимоги знадобиться двадцять тижнів практичного часу.
Знаючи попередню таблицю, дехто може спрогнозувати, скільки часу знадобиться для виконання великих партій вимог:

Інтуїція підказує, що вплив на тривалість циклу лінійно зростає. У десять разів більше роботи в середньому проштовхується через систему, тому в десять разів збільшується час циклу. Чотири тижні проти 40 тижнів.
Але це не працює так, тому що в систему вводиться більше варіативності. Що ж відбувається?
При 50-відсотковому завантаженні відношення циклу до часу обслуговування становить "5" у прикладі M[x]/M/1/∞. Це наближено відображає контрастні ситуації:

Все стало набагато гірше. Звичайно, це усереднені показники, які не можуть бути прийняті для будь-якого реального випадку, і ця модель є спрощеною абстракцією розробки.
Але саме тому розуміння теорії черг - і дії на основі цього розуміння - корисні для великомасштабної розробки, оскільки великі системи часто пов'язані з великими вимогами і великою роботою (вимоги, тестування, інтеграція, ...) великими партіями, що надходять у змінний час, з працівниками, які, як очікується, будуть на 100% використані (зайняті) весь час. Це може мати дивовижний вплив на середній час циклу.
Отже, наполягання на високому коефіцієнті використання працівників у цій ситуації з великими партіями робіт - це рецепт для... повільного виконання. Реальністю буде суперлінійне збільшення тривалості циклу.
Такий вплив на затримку і розмір черги не відповідає нашому інстинкту, оскільки люди не звикли аналізувати стохастичні системи з чергами. Хтось може подумати: "Якщо я зроблю робочий пакет в десять разів більшим, то вихід із системи займе в десять разів більше часу". Не варто на це розраховувати.
І ці затримки ще більше погіршуються при традиційній послідовній розробці, оскільки перед ними є низка процесів з чергами WIP; це ускладнює мінливість і додає ще більшого негативного впливу на загальну середню тривалість циклу.
Закон розміщення змінності [HS08] показує, що найгірше місце для змінності (з точки зору негативного впливу на тривалість циклу) - це передній кінець багатоетапної системи з чергами. Це те, що відбувається на першому етапі аналізу вимог з великими партіями специфікацій.
Висновок (Conclusion)
Отже, що ми дізналися?
- розробка продукту - це стохастична система з чергами, вона нелінійна і недетермінована
- поведінка стохастичної системи з чергами не піддається нашим інстинктам
- розмір партії, розмір вимог та рівень використання впливають на розмір черги та час циклу нелінійними випадковими способами, які не є очевидними - пропускна здатність може сповільнитися, якщо цього не розуміти
- розмір черги впливає на час циклу
- у змінній системі висока завантаженість збільшує час циклу і знижує пропускну здатність - це не допомагає; традиційний підхід до управління ресурсами [наприклад, McGrath04] може погіршити ситуацію, зосередившись на локальній оптимізації зайнятості робітників, а не на пропускній здатності системи
- система з мінливістю та низкою процесів і черг WIP ще більше погіршує затримку; ця ситуація описує традиційну послідовну розробку
- варіативність на передньому кінці багатоетапної системи з чергами має найгірший вплив
Приховані партії: Очі для партій (Hidden Batches: Eyes for Batches)
Якщо ви випікаєте три вишневі пироги одночасно, то зрозуміло, що є партія з трьох виробів. У розробці продукту все не так однозначно: Що саме означає "одна" вимога? На одному рівні "здійснювати операції з деривативами облігацій" - це одна вимога, але це також складова вимога або пакет під-вимог, які можна розділити. Ці приховані групи потрібно бачити.

Як ми бачили, система з чергами, що поводяться як модель M[x]/M/1/∞, і високим коефіцієнтом використання означає, що великі партії змінного розміру погано впливають на час циклу.
І так звані поодинокі великі елементи зі змінним розміром також погано впливають на час циклу, оскільки вони є прихованою великою партією. Отже, висновок для управління чергами в LeSS такий:
Щоб зменшити середню тривалість циклу, підтримуйте вільні місця в системі (не "зайняті на 100%") і (з часом, поступово) зменшуйте всі очевидно "поодинокі" великі позиції (вимоги) в Product Backlog до невеликих і приблизно однакових за розміром позицій.
Приховані черги: Очі за чергами (Hidden Queues: Eyes for Queues)
Коли люди приєднуються до Toyota, вони вчаться "бачити відходи". Вони вчаться бачити відходи в речах, про які раніше не думали, наприклад, в інвентаризації - чергах речей. Тепер, черги фізичних речей легко сприймаються людьми, і сприймаються як проблема...
Боже мій, там гігантська купа речей в черзі! Ви заробляєте на цій купі грошей? Чи є там дефекти? Чи потрібно його об'єднати з іншими речами, перш ніж ми зможемо його відправити? Чи потрібен нам - і чи зможемо ми заробити на кожній одиниці товару в цій купі?
Невидимі черги (Invisible queues) - у традиційному розвитку також існують всілякі черги, але через те, що вони невидимі, їх не сприймають як черги і не відчувають як проблеми. Якщо ви бізнесмен, який вклав десять мільйонів євро у створення гігантської купи частково зроблених речей, що лежать на підлозі і не приносять жодного прибутку, ви проходите повз неї, бачите її і відчуваєте біль та необхідність зрушити з місця.
І ви думаєте про те, щоб більше не створювати великі купи недороблених речей. Але люди, які займаються розробкою продуктів, насправді не бачать і не відчувають біль своїх черг.
Але вони існують. Черги WIP-інформації, документів та бітів на диску. Невидимі черги. Людям, які займаються розробкою продуктів, потрібен урок "Очі для черг", щоб вони могли почати сприймати те, що відбувається, і розвинути почуття нагальності щодо скорочення розмірів черг.
Візуальний менеджмент для реальних черг (Visual management for tangible queues) - Щоб розвинути "очі для черг" і почуття уваги, однією з практик ощадливого виробництва є візуальний менеджмент, створення фізичних жетонів (а не жетонів у комп'ютерній програмі) для цих черг.
Наприклад, популярною технікою є представлення всіх завдань для спринту на паперових картках, які розміщуються на стіні і пересуваються по мірі виконання завдань. Аналогічно можна зробити і з найбільш пріоритетними завданнями в Product Backlog.
Ці фізично відчутні картки роблять по-справжньому видимими невидимі черги, приховані всередині комп'ютера. Приховування цієї інформації в комп'ютерах суперечить меті ощадливого візуального (фізичного) управління і тому, що люди - з незліченними еволюційними інстинктами, які працюють з конкретними речами - повинні бачити і відчувати відчутні черги.
Непрямі вигоди від зменшення розміру партії та часу циклу (Indirect Benefits of Reducing Batch Size and Cycle Time)
"Навіщо це робити? Наші клієнти не хочуть випускати реліз кожні два тижні, а також не хочуть, щоб він був лише частковою вимогою".
Ми регулярно отримуємо це запитання від продуктових груп і бізнесменів. Вони ще не оцінили переваги невеликих партій у коротких циклах:
- Загальне скорочення часу циклу випуску, яке може бути досягнуте завдяки усуненню черг і застосуванню управління чергами, завдяки чому багато циклів розробки стають коротшими.
- Усунення пакетної затримки, коли одна функція невиправдано затримується через те, що вона рухається через систему разом з більшим пакетом інших вимог. Усунення цієї затримки надає бізнесу ще один ступінь свободи, щоб відправити менший продукт раніше з найбільш пріоритетними функціями.
- І останнє, але не менш важливе - це непрямі переваги, пов'язані з ефектом "озера і каміння", описаним далі.
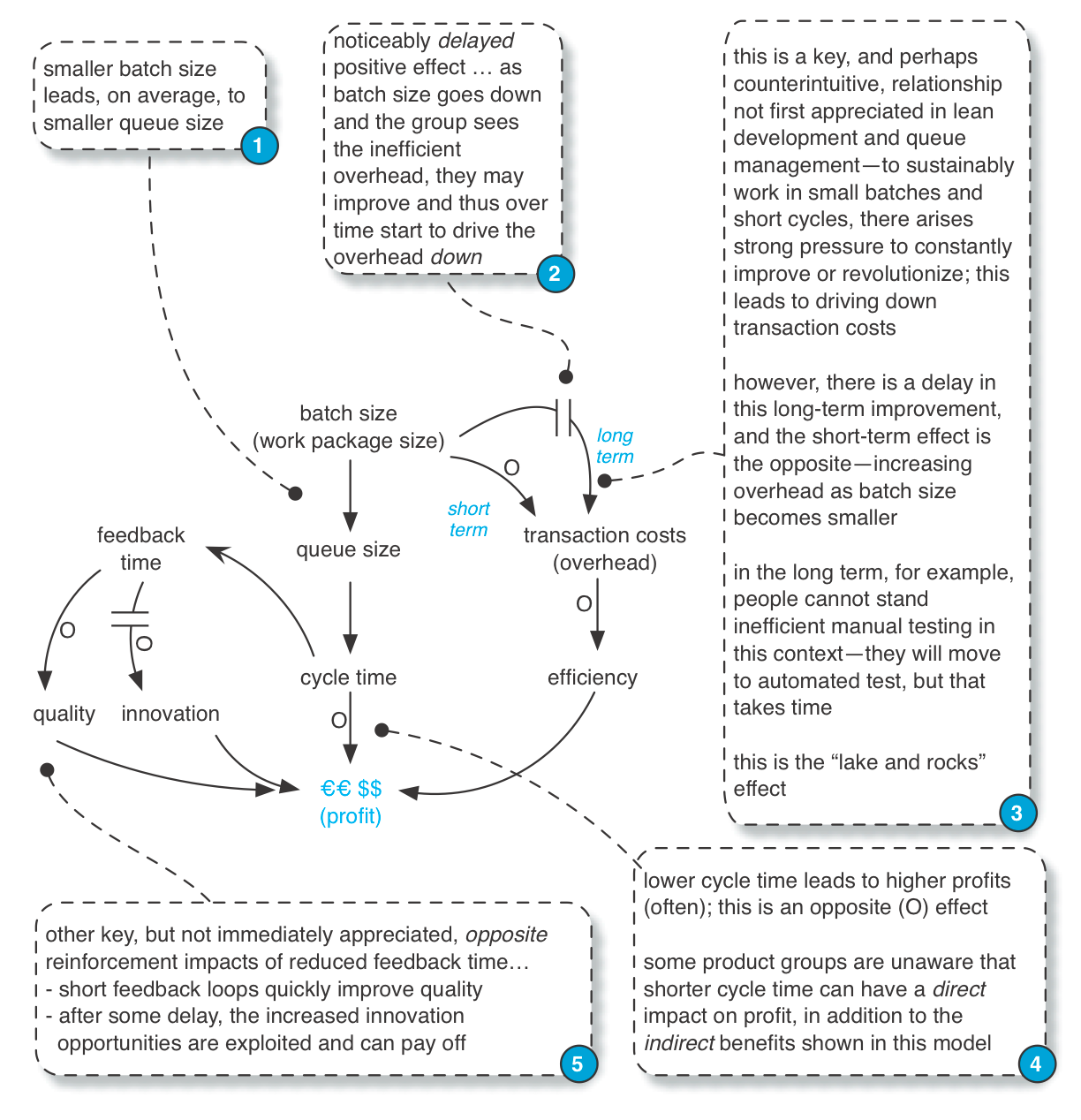
Непрямі вигоди: Метафора озера і скель (Indirect Benefits: The Lake and Rocks Metaphor)
Метафора, поширена в ощадливому виробництві: озеро і каміння. Глибина води може відображати рівень запасів, розмір партії, тривалість ітерації або час циклу. Коли вода висока (велика партія, розмір запасів або тривалість ітерації), багато каміння приховано.
Ці камені є слабкими місцями. Наприклад, розглянемо вісімнадцятимісячний цикл послідовних випусків з масовою передачею партій; неефективне тестування, інтеграція та погана співпраця - все це приховано під поверхнею такого довгого циклу і такої великої партії.
Але якщо ми попрацюємо з цією групою і попросимо: "Будь ласка, надайте невеликий набір невеликих функцій, які потенційно можуть бути відправлені через два тижні, кожні два тижні", то раптом всі неефективні практики стануть до болю очевидними.

Інакше кажучи, транзакційні витрати (накладні витрати) старого циклу процесу стають неприйнятними. Цей біль стає силою для вдосконалення, тому що люди не можуть витримати повторного переживання цього болю кожного короткого циклу, і, дійсно, досягнення цілей ітерації може бути просто неможливим при старій неефективній системі розробки.
Порада: Не всі "камені" великі або відразу помітні. Шлях до ощадливості - і шлях Скраму - полягає в тому, щоб почати з великих каменів, які є найбільш болісно очевидними, але рухомими, і з часом працювати над меншими перешкодами.
Ця діаграма причинно-наслідкових зв'язків (позначення пояснюється в Системному мисленні (Systems Thinking)) ілюструє ефект озера і каміння з точки зору моделі системної динаміки:
Застосування управління чергами в LeSS (Applying Queue Management in LeSS)
Існують десятки стратегій управління чергами. У книзі Дона Райнертсена "Управління дизайн-фабрикою" пояснюється багато з них. Однак ми хочемо зосередитися на кількох ключових кроках у контексті LeSS:
- змінити систему, щоб повністю викорінити черги
- навчитися бачити черги, що залишилися, за допомогою візуального управління
- зменшити варіативність
- обмежити розмір черги
Змінити систему - потрібно керувати існуючими чергами? Вийдіть за рамки. Наприклад, функціональні команди та приймання TDD і безперервне розгортання усувають багато черг у традиційній розробці.
Зменшіть варіативність - деякі люди спочатку намагаються зменшити черги за рахунок збільшення завантаження або багатозадачності (з негативними результатами), або за рахунок додавання нових розробників.
Дійсно, додавання людей - якщо вони талановиті - може допомогти (бувають винятки), але це дорого і займає багато часу. Люди, які розуміються на управлінні чергами, знають, з чого простіше почати: Зменшити варіабельність з особливих причин, що включає в себе зменшення розміру партії.
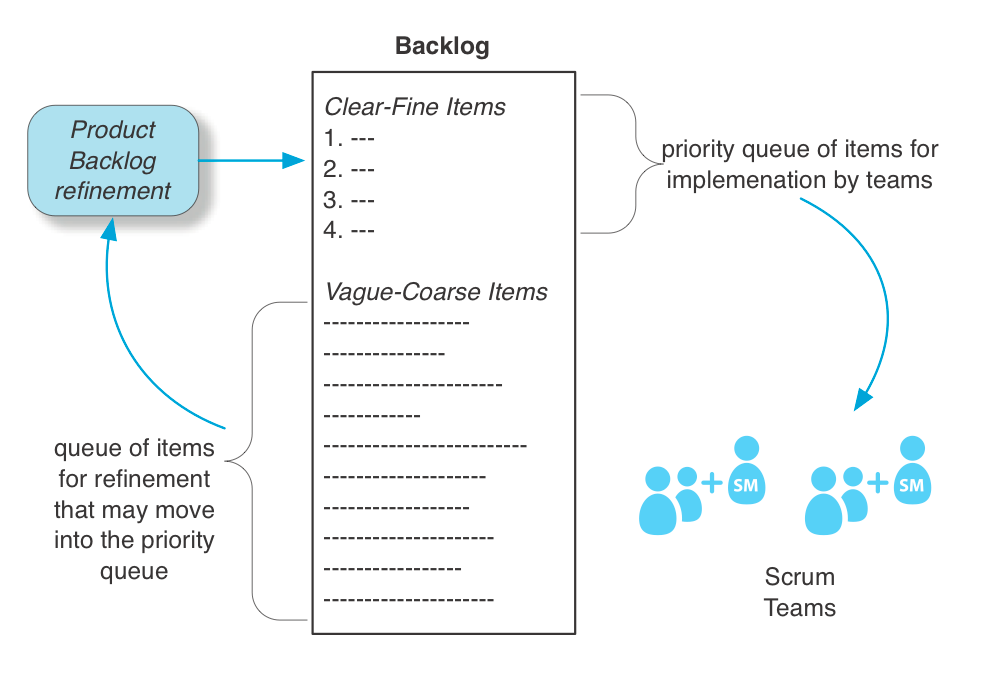
Можна розглядати Product Backlog як одну велику майже нескінченну чергу пріоритетів, але ми пропонуємо більш детальний погляд. Він має чіткі підмножини. Один погляд полягає в тому, що він містить дві підмножини: (1) список для поточного релізу (який в ідеалі є кожним спринт), і (2) "майбутній бэклог". Друга точка зору полягає в тому, що Product Backlog містить наступні дві підмножини:
- чітка-дрібна підгрупа елементів, які чітко проаналізовані, добре оцінені та достатньо дрібнозернисті, щоб виконати їх за значно менший час, ніж Спринт для однієї команди
- невизначено-груба підгрупа грубих елементів, які потребують більшого аналізу, оцінки та розбиття перед тим, як потрапити до чіткої підгрупи
Підмножини "поточний реліз" і "майбутній" можуть містити як чіткі, так і нечіткі елементи. На початку циклу випуску "поточний реліз", як правило, містить здебільшого нечітко-грубі елементи, і спринт за спринтом вони уточнюються до чітких і точних елементів, а потім реалізуються.
Це призводить до деяких ключових моментів:
- У LeSS прийнято - і доцільно - надавати пріоритет лише чіткій підмножині "поточного релізу".
- У LeSS ця "черга чітких пріоритетів" є критично важливою чергою робіт з впровадження перед командами.
- Невизначено-груба підмножина - це черга завдань, які подаються в процес Refinement of Product Backlog Refinement, який додає високоякісні невеликі завдання до підмножини чітких пріоритетів.
Перш ніж захоплюватися ідеєю зменшення варіативності... нова розробка - це не виробництво; без варіативності нічого нового не відбувається і не відкривається. Варіативність у дослідженнях і розробках є доречною і неминучою. Однак існують різновиди варіативності, які можна зменшити - тема цього розділу.
За термінологією Едвардса Демінга, існує варіабельність із загальних причин і варіабельність зі спеціальних причин.
Перша категорія - це загальна варіація шуму в процесі, і її нелегко пояснити конкретною причиною. З іншого боку, можна ідентифікувати варіації зі спеціальних причин, також відомі як варіації, що можуть бути визначені. Наприклад, варіація розміру запиту на функціонал є варіацією з конкретної причини.
А робота над погано проаналізованими незрозумілими вимогами - це відхилення з певної причини. Зменшуючи ідентифіковану варіативність з особливих причин - в меншій мірі або в робочих процесах - система з чергами покращила середню пропускну здатність.
Варіативність є одним з трьох джерел відходів в ощадливому мисленні (інші два - перевантаження і дії, що не додають цінності). Розуміння теорії черг може допомогти зрозуміти, чому варіативність вважається джерелом втрат.
Які існують джерела або види варіативності в LeSS?
- великі партії та великі товари
- невизначеність того, що означають елементи
- невизначеність щодо того, як розробляти/впроваджувати елементи
- різні (оціночні) зусилля для різних завдань
- кількість завдань у черзі з чітким пріоритетом "поточний реліз"
- розбіжність між оціночними та фактичними зусиллями, яка може відображати що/як, невизначеність, невміле оцінювання, навчання та багато іншого
- швидкість надходження завдань до черги з чітким пріоритетом поточного релізу
- командна та індивідуальна варіативність
- перевантаження або вихід з ладу спільних ресурсів, таких як тестова лабораторія
... і багато іншого. У термінології моделі масового обслуговування вони зазвичай зводяться до варіативності в обслуговуванні та швидкості прибуття.
В ощадливому мисленні потік є ключовим принципом, а потік вимагає зменшення або усунення варіативності. Ось чому вирівнювання - це також принцип ощадливого мислення; воно є протиотрутою від варіативності і допомагає рухатися до потоку.
Зменшення варіабельності LeSS через особливі причини (Reducing Special-Cause Variability in LeSS)
Це призводить до деяких пропозицій щодо зменшення варіабельності в LeSS з особливих причин:
Зменшити варіативність за рахунок невеликої черги (буферу) чітких, однакових за розміром користувацьких історій в Release Backlog - В Toyota використовується невеликий буфер високоякісного інвентарю, щоб згладити або вирівняти введення роботи в наступний процес. Цей інвентар (тимчасово необхідні відходи) позитивно підтримує вирівнювання рівня, оскільки команди розробників LeSS тепер мають чергу схожих за розміром елементів для роботи; ніякого очікування і менше сюрпризів. Елементи в нечіткій-грубій підмножині поточного релізу мають високу невизначеність "що/як" і є великими; тому обирати їх для реалізації невміло, оскільки це збільшує варіативність.
Зменшуйте варіативність, проводячи семінар з уточнення бэклогу продукту (Product Backlog Refinement, PBR) під час кожного спринту - в LeSS кожен спринт повинен включати PBR для підготовки елементів, щоб вони були готові до майбутніх спринтів. Це зменшує невизначеність і варіативність, а також зменшує варіативність оцінок, оскільки переоцінка може покращитися в міру того, як люди навчатимуться. Під час цієї вправи розділіть завдання на невеликі та приблизно однакові частини. Це зменшує розмір партії та пов'язану з ним варіативність. Це також зменшує затримку пакету - штучне стримування важливої підфункції через те, що вона застрягла в більшому пакеті функцій, деякі з яких є менш важливими. Ці повторювані майстер-класи також створюють регулярну каденцію додавання чітких елементів до черги, зменшуючи варіабельність у швидкості прибуття.
Зменшіть варіативність за допомогою стабільних команд функцій - Використовуйте стабільні довгоживучі команди функцій в LeSS, щоб зменшити варіативність в "серверах" - командах. Крім того, міжфункціональні, міжкомпонентні команди збільшують паралелізм і потік, оскільки елемент може потрапити до будь-якої з декількох доступних команд.
Зменшуйте варіативність за допомогою навчальних цілей з обмеженими часовими рамками - ця порада є найбільш корисною для доменів з великими вимогами, орієнтованими на дослідження. Вона зменшує неоднозначність і варіативність. Іноді нетривіальне дослідження потрібне лише для того, щоб почати розуміти функцію. Наприклад, одного разу ми консультували на об'єкті в Будапешті; група мобільних телекомунікаційних продуктів хотіла забезпечити "push to talk over cellular". Документ міжнародних стандартів для цього - тисячі сторінок. Навіть просто приблизно зрозуміти тему - це величезне зусилля. Один з підходів - попросити команду "вивчити тему". Але це нечітка необмежена робота, яка призведе до більшої варіативності послуг і може перетворитися на нераціональні відходи надмірної обробки. Альтернативний підхід, який пропонується в LeSS, полягає в тому, щоб запропонувати команді мету для навчання, обмежену часовими рамками та зусиллями. Можливо, конкретна мета полягає в тому, щоб представити звіт про дослідження в кінці спринту, на додаток до їхньої роботи з впровадження. Наприклад, "вступний звіт про push to talk, максимум 30 людино-годин". На дослідження і навчання витрачається рівномірний обсяг зусиль, збалансований з командою, яка також реалізовує елементи. Потім власник продукту може вирішити інвестувати більш обмежені зусилля в наступний цикл досліджень у майбутньому спринті (можливо, більш цілеспрямований, оскільки тема прояснюється), поки, нарешті, тема не стане достатньо зрозумілою для того, щоб люди могли почати писати, розділяти і оцінювати пункти.
Зменшення розміру черги в LeSS (Reducing Queue Sizes in LeSS)
Інший метод управління чергою полягає в обмеженні розміру черги. Це не обов'язково зменшує варіативність, але має інші переваги. У традиційній черзі незавершеного виробництва (FIFO) довга черга є проблемою, тому що на просування елемента вперед у черзі і, врешті-решт, на його завершення піде вічність - це пряма причина для обмеження розміру черги FIFO.
Ця проблема є менш згубною у черзі пріоритетів Product Backlog, оскільки вона може бути пересортована - щось щойно додане може переміститися на початок списку. Тим не менш, існують вагомі причини для обмеження кількості елементів у черзі пріоритетів поточного випуску:
- Довгий список дрібнозернистих складних функцій важко зрозуміти і розставити пріоритети. При розробці великих продуктів ми регулярно чуємо скарги від власників продукту на те, що бэклог занадто великий, щоб вони могли "розібратися в ньому".
- Великий бэклог, що складається з чітко проаналізованих, дрібно розбитих і добре оцінених елементів, зазвичай має певні інвестиції, пропорційні його розміру. Це WIP без жодної віддачі від цих інвестицій. Як завжди з незавершеним виробництвом чи інвентаризацією, це фінансовий ризик.
- Люди з часом забувають деталі. Всі позиції в підгрупі "ясно - добре" пройшли глибокий аналіз на семінарах з оптимізації продуктового бэклогу. Якщо цей список короткий, є велика ймовірність, що команда, яка виконує завдання, нещодавно проаналізувала його на воркшопі, можливо, протягом останніх двох місяців. Якщо черга дуже довга і постійно зростає, є більша ймовірність того, що команда візьметься за завдання, яке було проаналізовано давно. Навіть якщо на семінарі, ймовірно, буде письмова документація, яка була створена давно, вона, звичайно, буде недосконалою, а розуміння деталей буде нечітким і застарілим.
Висновок (Conclusion)
Управління чергою може стати молотком, який змусить вас шукати цвяхи для черги. Не піддавайтеся спокусі керувати існуючими чергами - це стандартне рішення проблеми. Замість цього розгляньте можливість впровадження системного кайдзену, щоб змінити базову систему таким чином, щоб черги більше не могли утворюватися або існувати.
Розпаралелювання з крос-функціональними командами та розробка на основі приймальних тестів є поширеними прикладами, але є й інші. Застосовуйте управління чергами - точкову тактику кайдзен - лише тоді, коли ви не можете викорінити чергу.
Рекомендована література (Recommended Readings)
Існують десятки, якщо не сотні, загальних текстів з теорії масового обслуговування. Ми ж пропонуємо літературу, яка встановлює зв'язок між цією темою та розробкою продукту:
- Managing the Design Factory Дона Рейнертсена - класичний вступ до теорії черг та розробки продукту.
- "Гнучка розробка продукту" Престона Сміта була першою широко популярною книгою про загальну розробку продукту, яка представила концепції гнучкої розробки програмного забезпечення, включаючи Scrum та екстремальне програмування, ширшій аудиторії. Цей текст містить аналіз теорії черг і варіативності, а також їхнього зв'язку з розробкою.
Джерела статті про Теорії черг
- https://less.works/less/principles/queueing_theory

